

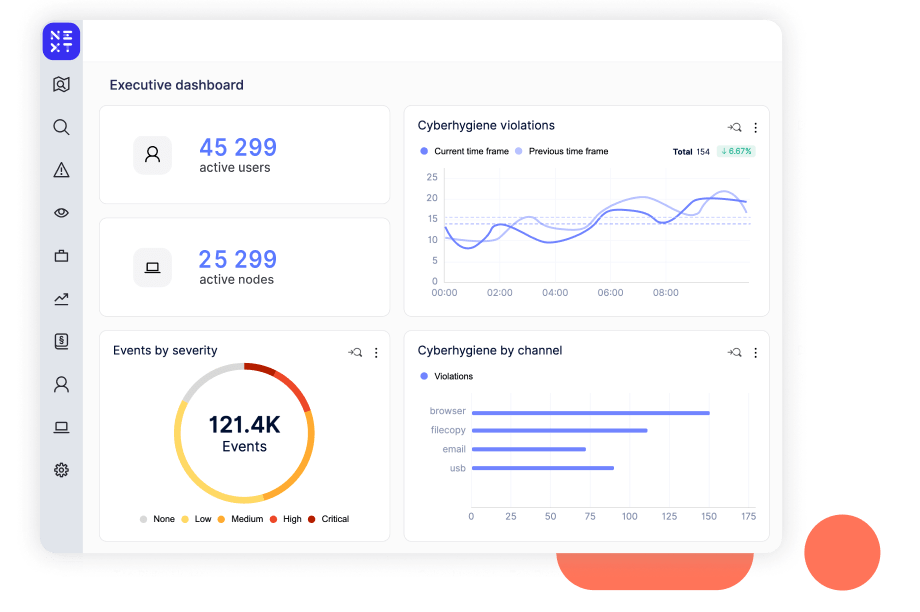
Reveal uncovers risk, educates employees, and fulfills security, compliance, and regulatory needs. Unlike legacy DLP, Reveal is a flexible, cloud-native, AI & ML powered solution built for today's threat landscape.
No wonder we're turning analysts' heads at Forrester, Gartner, Radicati, GigaOm and Quadrant Knowledge Solutions.
Reveal is a modern and unified approach to data protection combining Data Loss Prevention, Insider Risk Management and Cloud and Mobile Data Security. Unlike traditional approaches, Reveal doesn't require IT infrastructure, pre-built policies or multiple agents.
Reveal uses machine learning to instantly identify risk, including malicious insider behavior It has visibility into all data egress points, form managed endpoints to unmanaged mobile devices, to USB drives and printers, and SaaS apps like Slack, O365, and Google Workspace.
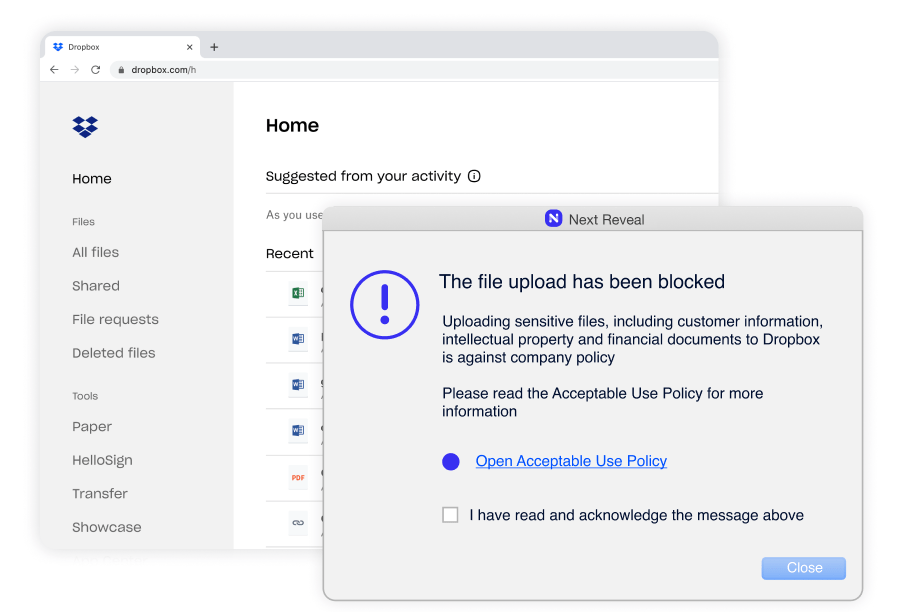
Unlike legacy DLP’s binary “block” OR “allow,” with Reveal you can respond as your business demands. Reveal’s adaptive controls let you decide what actions to take such as logging, isolating an endpoint, or blocking actions.
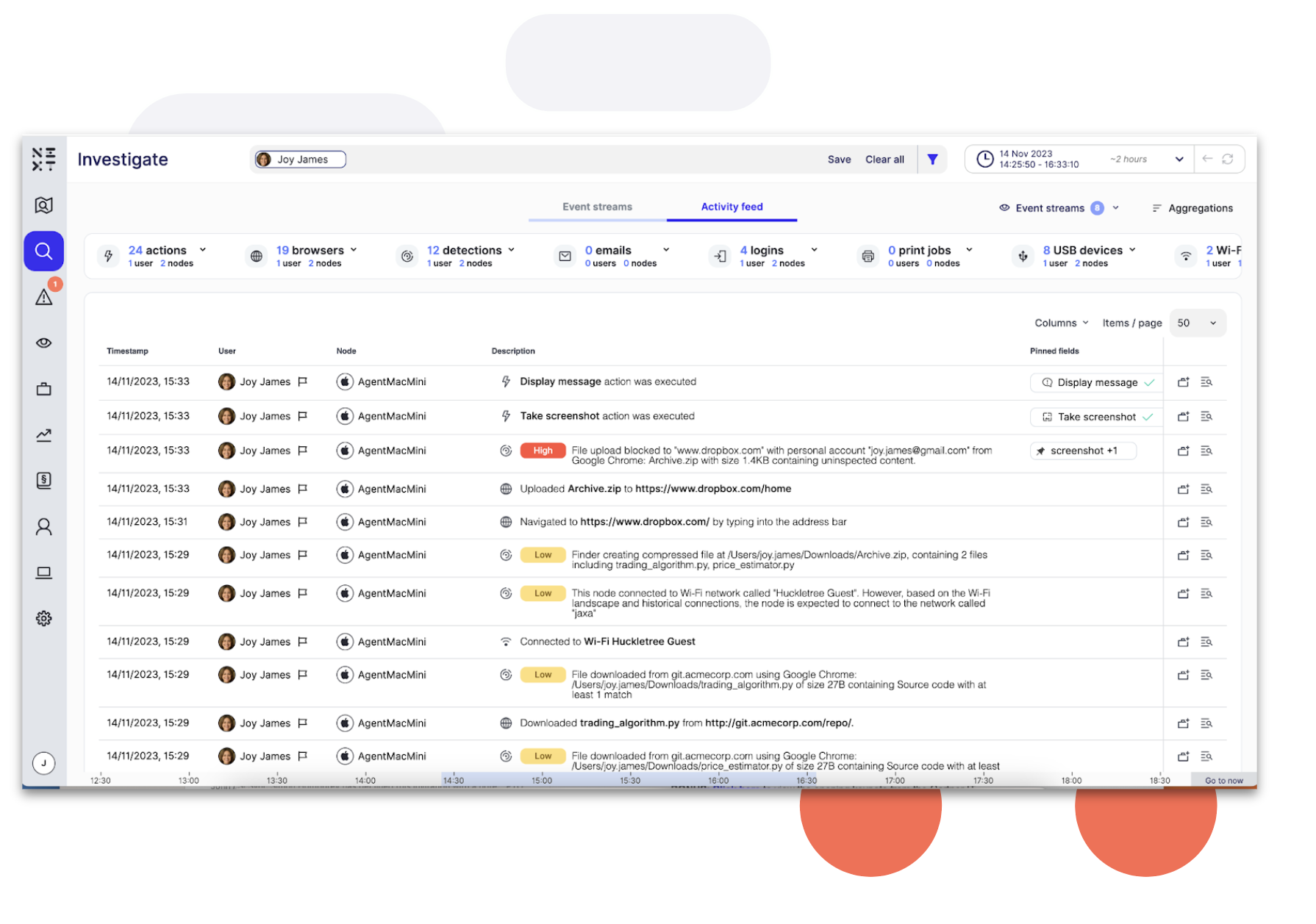
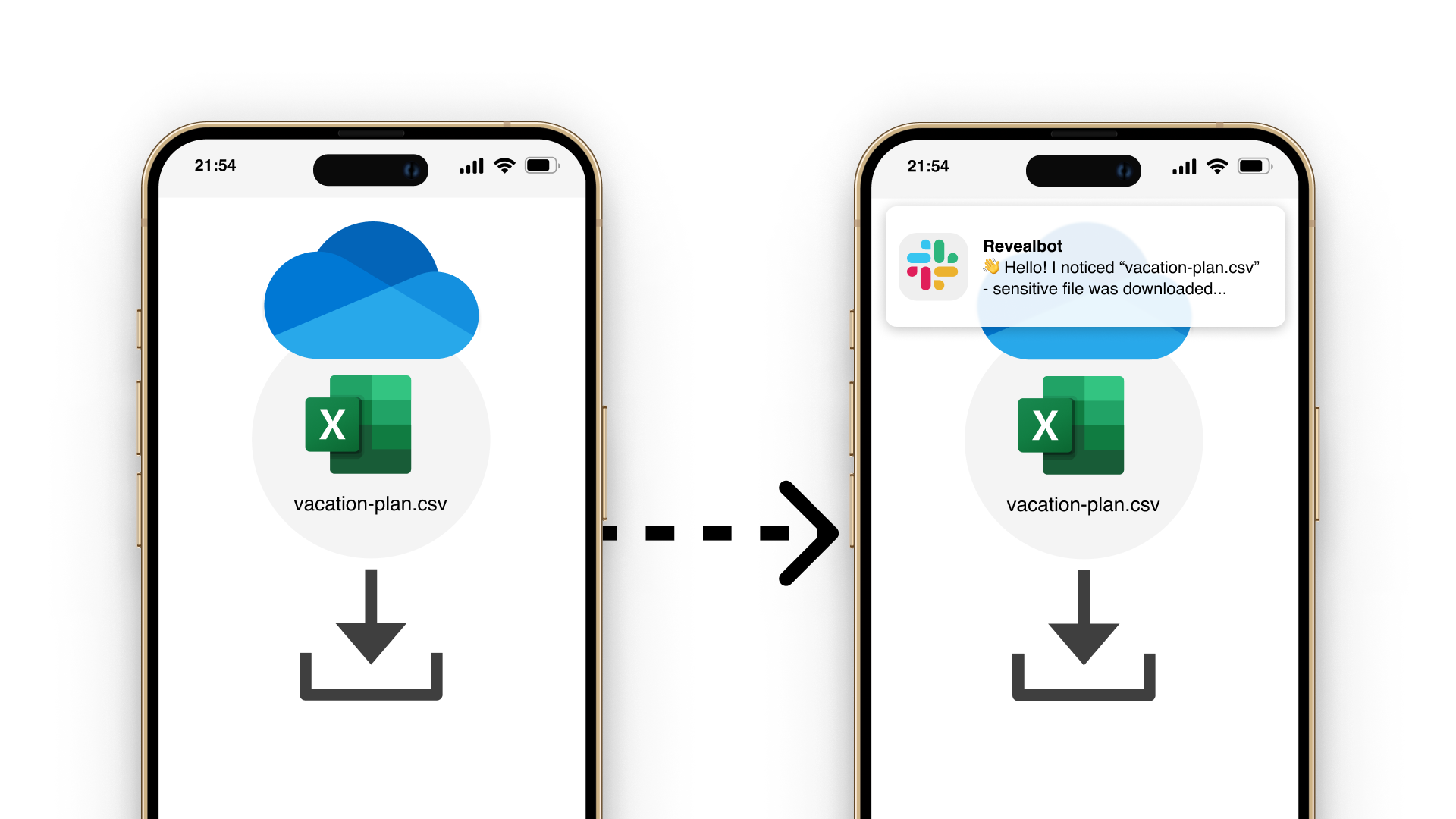
Reveal Beyond overcomes legacy DLP challenges by providing a unified platform for managing data security and extending insider threat visibility and data protection to Microsoft O365, Google Workspace and personal devices.
Reveal Beyond doesn’t require endpoint agents or on-prem technology and effectively addresses DLP and insider risk use cases commonly seen with the use of cloud drives and unmanaged personal devices. Investigation and remediation processes are streamlined to reduce exposure to security risks and compliance challenges.
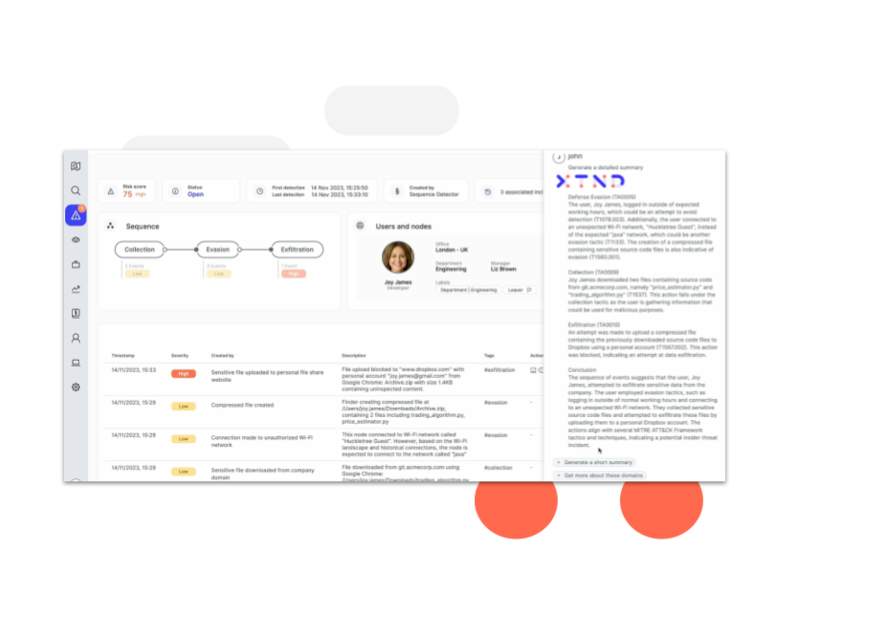
Reveal's AI-powered assistant, XTND, takes security analysts to the next level with streamlined data loss and insider threat analysis.
XTND enhances incident analysis by using GenAI to summarize and contextualize data associated with observed high risk activity, mapped to MITRE IT TTP, for easy consumption by analysts and peers. Analysts benefit from optimized workflows, a reduction in time to contain and resolve threats, and the empowerment to contribute to the business at a higher level.

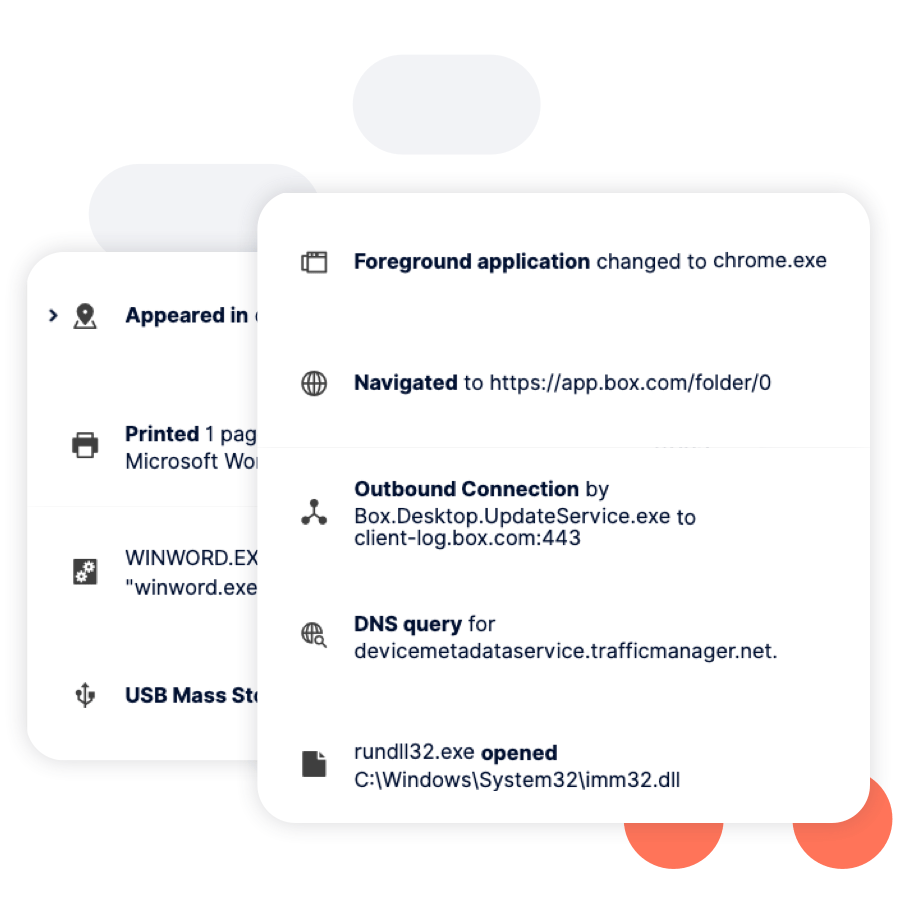
Reveal instantly provides visibility on installation. It collects telemetry data from system, user, and network events on the endpoint, providing insights into how endpoints are being used.
Unlike legacy DLP, you don’t have to build policies to gain visibility.
For customers who need more sophisticated policies, Reveal provides out-of-the-box policies for common use cases based on data, user and event context.

Next successfully completed ISO 27001 certification testing.

Next partners with MITRE to build on the MITRE ATT&CK® framework, forming the foundation for a threat-informed defense approach to counter the latest techniques leveraged by internal and external threat actors.

Reveal was recognized as a winner in the Best Data Leakage Prevention (DLP) Solution category for the SC Awards Europe 2023.

Along with developing a splunk integration app, Next is part of Splunk's partnerverse.

Cyber Defense Magazine named Reveal the most comprehensive Data Loss Prevention solution.
Reveal was listed as an “Outperformer” in the market leader category. In GigaOm’s words, Reveal is a “Leader in the Innovation half of the Radar, showing both a good range of capabilities and rapid innovation.”

Winner of 7/10 categories, including best overall performance in the insider threat simulation against seven industry-leading DLP, EDR, UBA, and SIEM vendors.

Reveal successfully completed certification testing with the Defense Information Systems Agency’s (DISA) Joint Interoperability Test Command (JITC).

Reveal is compliant with the CNSSD 504 and meets the key User Activity Monitoring (UAM) requirements defined by the NITTF.

Next DLP won Cyber Security Startup of the Year, exhibiting excellence, strong leadership, evidence of achievement, and innovation to receive this award.

Distinguished vendor with solution to the challenge of supporting the SOC Analysts.

